
GPU accelerated algorithm
Oct 2022
A GPU accelerated 2D convolution algorithm resulting in 230 times increased throughput for distance measuring robot
- Acceleration
- GPU
- C++
- Master
This project is part of the course Embedded Computer Architectures I of my master Embedded Systems at the University of Twente. It has been developed in collaboration with Thijs Bink, Jelle Hierck and Luuk van der Weide.
Our objective was to improve the performance of a 2D convolution algorithm. The input for the algorithm is the distance data of a scanning robot. The robot scans an arc of about 160° in 80 steps and reports the distance to any objects between itself and 3 meters using the ultrasonic distance sensor. The firmware of the robot has been developed by us as well earlier in the course.
The exercise forced us to transform the distance vector into a matrix of 80 x 300. This matrix is the input data for the convolution algorithm, which tries to smoothen the data as pre-processing for object detection.
We had no pre-existing knowledge of working with GPUs and so we dove deep into the Nvidia CUDA toolkit documentation. We discovered many optimization parameters and so we built a simple tool that helped us optimize for these. Our main concerns were to optimize block and warp utilization as well as using the least conditional statements as GPUs do not have any branch prediction. However, the latter did not have as much influence as we expected it to have.
To see our improvements, we measured the performance of the convolution algorithm on a single thread of a CPU. The baseline had a throughput of about 1600 matrices per second. We developed 3 methods to increase the throughput using an Nvidia GPU. All of these resulted in significant throughput improvements, where the best performance had a throughput of 374756 matrices per second. That is 230 times faster than the baseline. We had the best improvements of our class and were rewarded with a perfect score of 10 out of 10.
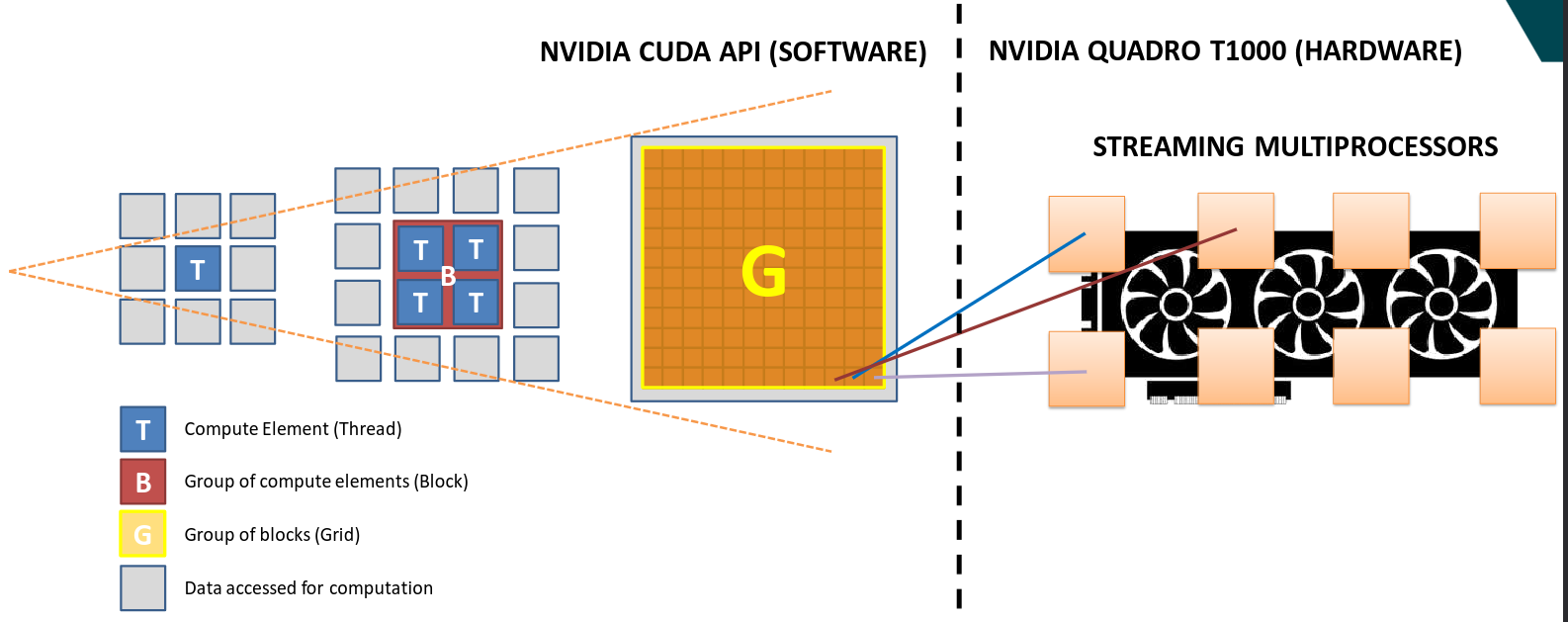
This image shows the hierarchy of a Nvidia GPU. Each thread of the GPU runs a kernel with the convolution algorithm, which access all memory surrounding the element the thread represents. These threads are bundled in blocks and all these blocks together construct the CUDA grid. The CUDA grid spans the complete application. Each block runs on a physical streaming multiprocessor of the GPU.